
YugabyteDB
YugabyteDB - the cloud native distributed SQL database for mission-critical applications.
- Project Website
- https://www.yugabyte.com/yugabytedb/
- Platform
- License
- other
- Category
- Technology
- MongoDB Python Typescript javascript Shell ruby PHP c++ Dockerfile Makefile HTML Batchfile SCSS CMake Perl Roff PLpgSQL M4 Jinja Scala Emacs Lisp Yacc Lex XS Assembly Mustache XSLT Jupyter Notebook sed DTrace
- Offers premium version?
- NO
- Proprietary?
- NO
- About
-
What is YugabyteDB?
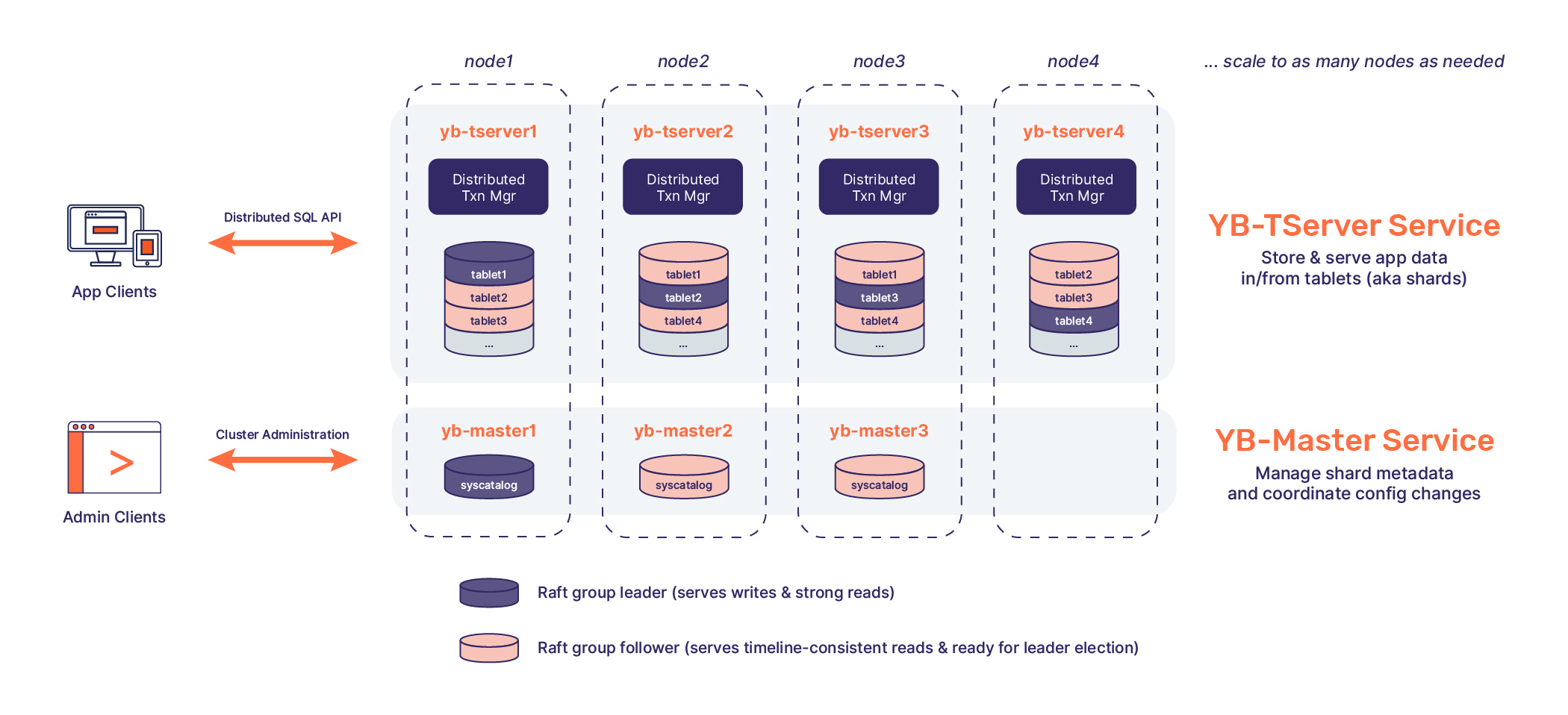
YugabyteDB is a high-performance, cloud-native, distributed SQL database that aims to support all PostgreSQL features. It is best suited for cloud-native OLTP (i.e., real-time, business-critical) applications that need absolute data correctness and require at least one of the following: scalability, high tolerance to failures, or globally-distributed deployments.
- Core Features
- Get Started
- Build Apps
- What's being worked on?
- Architecture
- Need Help?
- Contribute
- License
- Read More
Core Features
-
Powerful RDBMS capabilities Yugabyte SQL (YSQL for short) reuses the query layer of PostgreSQL (similar to Amazon Aurora PostgreSQL), thereby supporting most of its features (datatypes, queries, expressions, operators and functions, stored procedures, triggers, extensions, etc). Here is a detailed list of features currently supported by YSQL.
-
Distributed transactions The transaction design is based on the Google Spanner architecture. Strong consistency of writes is achieved by using Raft consensus for replication and cluster-wide distributed ACID transactions using hybrid logical clocks. Snapshot, serializable and read committed isolation levels are supported. Reads (queries) have strong consistency by default, but can be tuned dynamically to read from followers and read-replicas.
-
Continuous availability YugabyteDB is extremely resilient to common outages with native failover and repair. YugabyteDB can be configured to tolerate disk, node, zone, region, and cloud failures automatically. For a typical deployment where a YugabyteDB cluster is deployed in one region across multiple zones on a public cloud, the RPO is 0 (meaning no data is lost on failure) and the RTO is 3 seconds (meaning the data being served by the failed node is available in 3 seconds).
-
Horizontal scalability Scaling a YugabyteDB cluster to achieve more IOPS or data storage is as simple as adding nodes to the cluster.
-
Geo-distributed, multi-cloud YugabyteDB can be deployed in public clouds and natively inside Kubernetes. It supports deployments that span three or more fault domains, such as multi-zone, multi-region, and multi-cloud deployments. It also supports xCluster asynchronous replication with unidirectional master-slave and bidirectional multi-master configurations that can be leveraged in two-region deployments. To serve (stale) data with low latencies, read replicas are also a supported feature.
-
Multi API design The query layer of YugabyteDB is built to be extensible. Currently, YugabyteDB supports two distributed SQL APIs: Yugabyte SQL (YSQL), a fully relational API that re-uses query layer of PostgreSQL, and Yugabyte Cloud QL (YCQL), a semi-relational SQL-like API with documents/indexing support with Apache Cassandra QL roots.
-
100% open source YugabyteDB is fully open-source under the Apache 2.0 license. The open-source version has powerful enterprise features such as distributed backups, encryption of data-at-rest, in-flight TLS encryption, change data capture, read replicas, and more.
Read more about YugabyteDB in our FAQ.
Get Started
- Quick Start
- Try running a real-world demo application:
Cannot find what you are looking for? Have a question? Please post your questions or comments on our Community Slack or Forum.
Build Apps
YugabyteDB supports many languages and client drivers, including Java, Go, NodeJS, Python, and more. For a complete list, including examples, see Drivers and ORMs.
What's being worked on?
This section was last updated in May, 2023.
Current roadmap
Here is a list of some of the key features being worked on for the upcoming releases (the YugabyteDB v2.17 preview release has been released in Jan, 2023, and the v2.16 stable release was released in Jan 2023).
Feature Status Release Target Progress Comments
Automatic tablet splitting enabled by default PROGRESS v2.18 Track Enables changing the number of tablets (which are splits of data) at runtime.
Upgrade to PostgreSQL v15 PROGRESS v2.21 Track For latest features, new PostgreSQL extensions, performance, and community fixes
Database live migration using YugabyteDB Voyager PROGRESS
Track Database live migration using YugabyteDB Voyager
Support wait-on-conflict concurrency control PROGRESS v2.19 Track Support wait-on-conflict concurrency control
Support for transactions in async xCluster replication
PROGRESS v2.19 Track Apply transactions atomically on target cluster.
YSQL-table statistics and cost based optimizer(CBO) PROGRESS v2.21 Track Improve YSQL query performance
YSQL-Feature support - ALTER TABLE PROGRESS v2.21 Track Support for various
ALTER TABLEvariantsSupport for GiST indexes PLANNING
Track Support for GiST (Generalized Search Tree) based index
Connection Management PROGRESS
Track Server side connection management
Recently released features
Feature Status Release Target Docs / Enhancements Comments
Faster Bulk-Data Loading in YugabyteDB ✅ DONE
v2.15 Track Faster Bulk-Data Loading in YugabyteDB
Change Data Capture ✅ DONE
v2.13
Change data capture (CDC) allows multiple downstream apps and services to consume the continuous and never-ending stream(s) of changes to Yugabyte databases
Support for materalized views ✅ DONE
v2.13 Docs A materialized view is a pre-computed data set derived from a query specification and stored for later use
Geo-partitioning support for the transaction status table ✅ DONE
v2.13 Docs Instead of central remote transaction execution metatda, it is now optimized for access from different regions. Since the transaction metadata is also geo partitioned, it eliminates the need for round-trip to remote regions to update transaction statuses.
Transparently restart transactions ✅ DONE
v2.13
Decrease the incidence of transaction restart errors seen in various scenarios
Row-level geo-partitioning ✅ DONE
v2.13 Docs Row-level geo-partitioning allows fine-grained control over pinning data in a user table (at a per-row level) to geographic locations, thereby allowing the data residency to be managed at the table-row level.
YSQL-Support
GINindexes ✅ DONEv2.11 Docs Support for generalized inverted indexes for container data types like jsonb, tsvector, and array
YSQL-Collation Support ✅ DONE
v2.11 Docs Allows specifying the sort order and character classification behavior of data per-column, or even per-operation according to language and country-specific rules
YSQL-Savepoint Support ✅ DONE
v2.11 Docs Useful for implementing complex error recovery in multi-statement transaction
xCluster replication management through Platform ✅ DONE
v2.11 Docs
Spring Data YugabyteDB module ✅ DONE
v2.9 Track Bridges the gap for learning the distributed SQL concepts with familiarity and ease of Spring Data APIs
Support Liquibase, Flyway, ORM schema migrations ✅ DONE
v2.9 Docs
Support
ALTER TABLEadd primary key ✅ DONEv2.9 Track
YCQL-LDAP Support ✅ DONE
v2.8 Docs support LDAP authentication in YCQL API
Platform Alerting and Notification ✅ DONE
v2.8 Docs To get notified in real time about database alerts, user defined alert policies notify you when a performance metric rises above or falls below a threshold you set.
Platform API ✅ DONE
v2.8 Docs Securely Deploy YugabyteDB Clusters Using Infrastructure-as-Code
Architecture
Review detailed architecture in our Docs.
Need Help?
-
You can ask questions, find answers, and help others on our Community Slack, Forum, Stack Overflow, as well as Twitter @Yugabyte
-
Please use GitHub issues to report issues or request new features.
-
To Troubleshoot YugabyteDB, cluser/node level issues, Please refer to Troubleshooting documentation
Contribute
As an open-source project with a strong focus on the user community, we welcome contributions as GitHub pull requests. See our Contributor Guides to get going. Discussions and RFCs for features happen on the design discussions section of our Forum.
License
Source code in this repository is variously licensed under the Apache License 2.0 and the Polyform Free Trial License 1.0.0. A copy of each license can be found in the licenses directory.
The build produces two sets of binaries:
- The entire database with all its features (including the enterprise ones) are licensed under the Apache License 2.0
- The binaries that contain
-managedin the artifact and help run a managed service are licensed under the Polyform Free Trial License 1.0.0.
By default, the build options generate only the Apache License 2.0 binaries.
Read More
- To see our updates, go to The Distributed SQL Blog.
- For an in-depth design and the YugabyteDB architecture, see our design specs.
- Tech Talks and Videos.
- See how YugabyteDB compares with other databases.
-
High performance data store solution1.4K
-
🥑 ArangoDB is a native multi-model database with flexible data models for documents, graphs, and key-values. Build high performance applications using a convenient SQL-like query language or JavaScript extensions.13.2K
-
Meet BigchainDB. The blockchain database.4.01K
-
ClickHouse® is a free analytics DBMS for big data32K
-
CockroachDB - the open source, cloud-native distributed SQL database.
-
Top-level source repository for Couchbase Server source code and build projects216
-
CrateDB is a distributed SQL database that makes it simple to store and analyze massive amounts of data in real-time. Built on top of Lucene.3.81K
-
Production PostgreSQL for Kubernetes, from high availability Postgres clusters to full-scale database-as-a-service.3.54K
-
General-purpose bitemporal database for SQL, Datalog & graph queries. Developed by @juxt2.39K
-
Databend is a modern Elasticity and Performance cloud data warehouse, activate your object storage for real-time analytics. Databend Serverless at https://app.databend.com/6.76K
-
Apache Doris is an easy-to-use, high performance and unified analytics database.10.2K
-
A modern replacement for Redis and Memcached21.7K
-
Apache Druid: a high performance real-time analytics database.13K
-
FoundationDB - the open source, distributed, transactional key-value store13.4K
-
A One-Stop Large-Scale Graph Computing System from Alibaba2.98K
-
GreptimeDB is an open-source, cloud-native time series database which also has powerful analytical features3.24K
-
Open-source distributed computation and storage platform. Real-time Stream Processing Unconference. Save Your Spot https://hazelcast.com/lp/unconference/
-
IBM Db2® is a family of hybrid data management products offering a complete suite of AI empowered capabilities designed to help you manage both structured and unstructured data on premises as well as in private and public cloud environments. Db2 is built on an intelligent common SQL engine designed for scalability and flexibility.
-
Iguazio is a data science platform that enables them to develop, deploy, and manage AI applications at scale and in real-time.
-
Infinispan is an open source data grid platform and highly scalable NoSQL cloud data store.1.09K
-
InterSystems is a vendor of software and technology for high-performance database management, integration, and health information systems.
-
MariaDB server is a community developed fork of MySQL server. Started by core members of the original MySQL team, MariaDB actively works with outside developers to deliver the most featureful, stable, and sanely licensed open SQL server in the industry.5.07K
-
Data-Driven. Faster Insights. Breakthrough Performance. In-Memory Technology. Hybrid Data Platform.
-
Enmotech is a global supplier of end-to-end solutions of data assets.
-
MySQL Server, the world's most popular open source database, and MySQL Cluster, a real-time, open source transactional database.9.74K
-
A distributed, fast open-source graph database featuring horizontal scalability and high availability9.7K
-
The versioned, forkable, syncable database7.45K
-
NuoDB is a provider of distributed SQL database for cloud applications.
-
The industry’s leading database continues to deliver leading-edge innovations, including machine learning, to enable self-driving data management.
-
OrientDB is the most versatile DBMS supporting Graph, Document, Reactive, Full-Text and Geospatial models in one Multi-Model product. OrientDB can run distributed (Multi-Master), supports SQL, ACID Transactions, Full-Text indexing and Reactive Queries.4.65K
-
A crazy fast analytical database, built on bitmaps. Perfect for ML applications. Learn more at: http://docs.featurebase.com/. Start a Docker instance: https://hub.docker.com/r/featurebasedb/featurebase2.51K
-
Mirror of the official PostgreSQL GIT repository. Note that this is just a *mirror* - we don't work with pull requests on github. To contribute, please see https://wiki.postgresql.org/wiki/Submitting_a_Patch13.7K
-
The official home of the Presto distributed SQL query engine for big data15.3K
-
Qubole is a simple and secure data lake platform for machine learning, streaming, and ad-hoc analytics.
-
Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps.62.5K
-
The open-source database for the realtime web.26.4K
-
Universal transaction manager428
-
A Kubernetes operator for declarative database schema management (gitops for database schemas)910
-
NoSQL data store using the seastar framework, compatible with Apache Cassandra11.6K
-
🔥 Seata is an easy-to-use, high-performance, open source distributed transaction solution.24.6K
-
Ecosystem to transform any database into a distributed database system, and enhance it with sharding, elastic scaling, encryption features & more19K
-
SingleStore is a provider of a database for operational analytics and cloud-native applications.
-
Snowflake is a cloud data platform that provides a data warehouse-as-a-service designed for the cloud.
-
With Adabas for LUW, you can deliver extremely high transaction speeds with a fraction of the staff and system resources needed for comparable database management systems.
-
Open source permissions database inspired by Google Zanzibar4.03K
-
Cloud Native PostgreSQL High Availability4.37K
-
In-memory computing platform consisting of a database and an application server3.27K
-
TDengine is an open source, high-performance, cloud native time-series database optimized for Internet of Things (IoT), Connected Cars, Industrial IoT and DevOps.22.3K
-
TiDB is an open-source, cloud-native, distributed, MySQL-Compatible database for elastic scale and real-time analytics. Try AI-powered Chat2Query free at : https://tidbcloud.com/free-trial35.3K
-
A distributed transactional key-value database. Based on the design of Google Spanner and HBase, but simpler to manage and without dependencies on any distributed filesystem13.9K
-
PostgreSQL for time‑series. TimescaleDB is the leading open-source relational database for time-series data. Fully managed or self‑hosted.
-
The core analytical platform within the Micro Focus software portfolio, Vertica is the Unified Analytics Platform, based on a massively scalable architecture with the broadest set of analytical capabilities and end-to-end in-database machine learning.
-
MySQL-compatible, horizontally scalable, cloud-native database solution.17.1K
-
VoltDB is a high-velocity decisioning engine, powering real-time applications that must react in milliseconds.2.03K
-
Weaviate is an open source vector database that stores both objects and vectors, allowing for combining vector search with structured filtering with the fault-tolerance and scalability of a cloud-native database, all accessible through GraphQL, REST, and various language clients.8.31K
-
Yellowbrick offers a SQL data warehouse built from the ground up on Kubernetes.
-
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information.
-
Apache Heron (Incubating) is a realtime, distributed, fault-tolerant stream processing engine from Twitter3.64K
-
Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications.20.1K
-
Apache Spark - A unified analytics engine for large-scale data processing37.3K
-
Mirror of Apache Storm6.51K
-
Event Hubs is a fully managed, real-time data ingestion service that’s simple, trusted, and scalable.
-
Apache Beam is a unified programming model for Batch and Streaming data processing.7.26K
-
A common specification for Continuous Delivery events107
-
Standardizing common eventing metadata and their location to help with event identification and routing.4.46K
-
The most scalable open-source MQTT broker for IoT, IIoT, and connected vehicles12.6K
-
An intelligent event streaming platform2.25K
-
Cloud Dataflow is a fully-managed service for transforming and enriching data in stream (real time) and batch (historical) modes with equal reliability and expressiveness -- no more complex workarounds or compromises needed. And with its serverless approach to resource provisioning and management, you have access to virtually limitless capacity to solve your biggest data processing challenges, while paying only for what you use.
-
Distributed Stream and Batch Processing
-
KubeMQ is a Kubernetes Message Queue Broker622
-
Lightbend offers a reactive application development platform for building distributed applications and modernizing aging infrastructures.
-
Next-Generation Event Processing Platform3K
-
NATS.io is a connective technology for distributed systems and is a perfect fit to connect devices, edge, cloud or hybrid deployments. True multi-tenancy makes NATS ideal for SaaS and self-healing and scaling technology allows for topology changes anytime with zero downtime.13.9K
-
Cloud-oriented, simple, flexible, vendor-neutral and language-independent standards for messaging720
-
Data-Centric Pipelines and Data Versioning
-
Pravega - Streaming as a new software defined storage primitive1.93K
-
Apache Pulsar - distributed pub-sub messaging system13.4K
-
Open source RabbitMQ: core server and tier 1 (built-in) plugins11.2K
-
Redpanda is a streaming data platform for developers. Kafka API compatible. 10x faster. No ZooKeeper. No JVM!
-
SeaTunnel is a distributed, high-performance data integration platform for the synchronization and transformation of massive data (offline & real-time).6.75K
-
Stream Processing and Complex Event Processing Engine1.48K
-
Kubernetes-native data streaming powered by Apache Kafka4.14K
-
Talend specializes in cloud data integration and data integrity.
-
Main Tremor Project Rust Codebase791
-
Alibaba Cloud develops highly scalable cloud computing and data management services.
-
Find, install and publish Kubernetes packages1.42K
-
Backstage is an open platform for building developer portals24.3K
-
Tanzu Application Catalog is a customizable selection of open source software from the Bitnami collection that is continuously maintained and verifiably tested for use in production environments.
-
CLI for building apps using Cloud Native Buildpacks2.28K
-
Carvel provides a set of reliable, single-purpose, composable tools that aid in your application building, configuration, and deployment to Kubernetes.1.51K
-
Modern applications with built-in automation2.53K
-
Build SaaS for your containerized applications558
-
Tools for local collaborative development in pre-production Kubernetes clusters
-
DeployHub makes it easy for IT Engineers to govern their microservice supply chain and deliver secure, high-quality microservices at scale.
-
Kube-native API for cloud development workspaces specification211
-
DevSpace - The Fastest Developer Tool for Kubernetes ⚡ Automate your deployment workflow with DevSpace and develop software directly inside Kubernetes.3.87K
-
Define and run multi-container applications with Docker31.1K
-
The Kubernetes-Native IDE for Developer Teams6.89K
-
Gefyra runs local code in any Kubernetes cluster without the build and push cycle. It overlays containers in the cluster making code changes immediately available.581
-
Always ready to code - spin up fresh, automated dev environments for each task, in the cloud, in seconds.
-
Gradle is a build automation tool for multi-language software development. It controls the development process in the tasks of compilation and packaging to testing, deployment, and publishing. Supported languages include Java (Kotlin, Groovy, Scala), C/C++, and JavaScript.15.5K
-
The Kubernetes Package Manager25.3K
-
Containerized developer environments in a browser - onboard developers fast and prevent code exfiltration with precise security controls. Devs launch spaces with all their tools pre-installed and start coding in seconds.
-
Build Container Images In Kubernetes13.2K
-
Build and deploy Go applications6.75K
-
Documentation for Konveyor Community6
-
KOTS provides the framework, tools and integrations that enable the delivery and management of 3rd-party Kubernetes applications, a.k.a. Kubernetes Off-The-Shelf (KOTS) Software.'860
-
Kubernetes Rust State Machine Operator143
-
KubeCarrier is an open source system for managing applications and services across multiple Kubernetes clusters. It provides a framework to centralize the management of services and provide these services with external users in a self service hub.297
-
Test your application on Kubernetes in a brand new simple way⚡ 轻量高效的微服务本地联调测试工具460
-
The Modern Application Platform.5.77K
-
Kubernetes Virtualization API and runtime in order to define and manage virtual machines.4.72K
-
Kubernetes Universal Declarative Operator (KUDO)1.14K
-
A hybrid command-line/UI development experience for cloud-native development2.68K
-
Build and Deploy System for OpenShift & Kubernetes508
-
Mia-Platform is the leading end-to-end Digital Integration Hub on the market. Its DevOps Console helps to manage Kubernetes clusters, define environments, set up test automation, design and run CI/CD pipelines, and guarantee an effective and efficient governance by controlling all the services – like Git, Jenkins, Docker, Nexus, Kubernetes, Terraform, Prometheus, Kibana and many others - from a single tool.
-
mirrord is an open-source tool that lets developers run local processes in the context of their cloud environment. It provides the benefits of running your service on a cloud environment (e.g. staging) without actually going through the hassle of deploying it there, and without disrupting the environment by deploying untested code.3.09K
-
Monokle is your friendly desktop UI for managing Kubernetes manifests. Monokle helps you quickly get a high-level view of your manifests and their contained resources, easily edit resources without having to learn yaml syntax, diff resources against your cluster, preview and debug resources generated with kustomize or Helm, and more. Monokle is created and maintained by Kubeshop.1.37K
-
Nocalhost is Cloud Native Dev Environment.1.7K
-
Highly extensible platform for developers to better understand the complexity of Kubernetes clusters.6.26K
-
Develop your applications directly in your Kubernetes Cluster3.07K
-
On-Prem provides an easy way to build on-premises virtual appliances designed for enterprise deployments. The On-Prem Meta appliance manages the appliance build lifecycle, and can be paired with continous integration systems.
-
Open Application Model (OAM).2.92K
-
Open Service Broker API Specification1.17K
-
The OpenAPI Specification Repository27.5K
-
SDK for building Kubernetes applications. Provides high level APIs, useful abstractions, and project scaffolding.6.82K
-
Packer is a tool for creating identical machine images for multiple platforms from a single source configuration.14.7K
-
Podman: A tool for managing OCI containers and pods.19.9K
-
Raftt saves developers from the frustrations of configuring, maintaining, and sharing development environments on their local machine.
-
Build, Share and Run Both Your Kubernetes Cluster and Distributed Applications (Project under CNCF)1.96K
-
Serverless Workflow Specification647
-
ServiceComb Java Chassis is a Software Development Kit (SDK) for rapid development of microservices in Java, providing service registration, service discovery, dynamic routing, and service management features1.88K
-
Community documentation for Shipwright16
-
Easy and Repeatable Kubernetes Development14.4K
-
The debugger for microservices1.73K
-
Tanka is a composable configuration utility for Kubernetes. It leverages the Jsonnet language to realize flexible, reusable and concise configuration.2.12K
-
Local development against a remote Kubernetes or OpenShift cluster6.12K
-
Define your dev environment as code. For microservice apps on Kubernetes.7K
-
Open Source CI/CD platform with advanced features and architecture. Powerful, reproducible and containerized workflows (called Runs), git based workflow (integrates with all the primary git repositories like GitHub, GitLab, Gitea), restart Runs from failed tasks, user direct runs (test your local changes to a remote Agola server with just one command), distributed and high available by design and runs everywhere (Kubernetes, docker, IaaS, bare metal).1.38K
-
Akuity is the enterprise-grade company for Argo, the open source suite of cloud native application delivery tools. Akuity was founded by Argo originators Hong Wang, Jesse Suen and Alexander Matyushentsev, and its mission is to empower DevOps teams to deliver their apps in a simpler, safer, and faster way. The Akuity Platform provides a best-in-class developer experience with enterprise readiness, and enables organizations to modernize their toolchain for the cloud-native era.
-
Appveyor Systems Inc. aim is to give powerful continuous integration and deployment tools to every .NET developer.
-
Kubernetes-native tools to run workflows, manage clusters, and do GitOps right.14.8K
-
AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. CodePipeline automates the build, test, and deploy phases of your release process every time there is a code change, based on the release model you define.
-
Continuously build, test, and deploy to any platform and cloud
-
Bamboo Server is the choice of professional teams for continuous integration, deployment, and delivery
-
Event-driven scripting for Kubernetes2.4K
-
Buildkite is a platform for running fast, secure, and scalable continuous integration pipelines on your own infrastructure.
-
Bunnyshell is an EaaS platform that enables fast, dead-simple environment creation and management for teams and developers who want to release better code faster.
-
Reliable Database CI/CD for Developers and DBAs7.56K
-
CAEPE is a Continuous Deployment platform for Kubernetes. With CAEPE, deploy applications on Kubernetes with confidence.
-
Cartographer is a Kubernetes-native Choreographer providing higher modularity and scalability for the software supply chain.432
-
CircleCI is a continuous integration and delivery platform that automates development workflows and IT operations.
-
Skycap is the easiest way to deploy and run applications on any existing Kubernetes cluster.
-
Ship faster with CI/CD as a Service
-
The World's Most Powerful CI/CD Platform
-
Concourse is a container-based continuous thing-doer written in Go.7.04K
-
Dispatch is a cloud native CI/CD platform for enabling enterprises to adopt GitOps methodologies running on Kubernetes.
-
Open source Software delivery workflow for Kubernetes3.63K
-
Progressive delivery Kubernetes operator (Canary, A/B Testing and Blue/Green deployments)4.51K
-
Open and extensible continuous delivery solution for Kubernetes. Powered by GitOps Toolkit.5.5K
-
GitHub Actions makes it easy to automate all your software workflows, now with world-class CI/CD. Build, test, and deploy your code right from GitHub. Make code reviews, branch management, and issue triaging work the way you want.
-
GitLab CE Mirror | Please open new issues in our issue tracker on GitLab.com23.4K
-
Main repository for GoCD - Continuous Delivery server6.94K
-
Cloud Build lets you build software quickly across all languages. Get complete control over defining custom workflows for building, testing, and deploying across multiple environments such as VMs, serverless, Kubernetes, or Firebase.
-
Harness is a Continuous Delivery-as-a-Service platform for engineering and DevOps teams to release applications into production.
-
An app-centric abstraction framework over K8s and an enterprise platform for accelerating deployments to multi-cloud Kubernetes. Offers self-service app deployments, container sprawl management across clusters, and DevSecOps.443
-
Jenkins X provides automated CI+CD for Kubernetes with Preview Environments on Pull Requests using Cloud Native pipelines from Tekton4.45K
-
k6 is a developer-centric, free and open-source load testing tool built for making performance testing a productive and enjoyable experience. Using k6, you'll be able to catch performance regression and problems earlier, allowing you to build resilient systems and robust applications.22.2K
-
Test generation for Developers. Generate tests and stubs for your application that actually works!2.52K
-
Cloud-native application life-cycle orchestration. Keptn automates your SLO-driven multi-stage delivery and operations & remediation of your applications.1.81K
-
Liquibase helps release software faster by bringing DevOps to the database4.18K
-
Octopus Deploy sets the standard for deployment automation for DevOps. We help software teams deploy freely - when and where they need, in a routine way. From modern containers and microservices to trusted legacy applications, Octopus orchestrates software delivery in data centers, multi-cloud, and hybrid IT infrastructure.
-
Standardizing Feature Flagging for Everyone88
-
Repository for top-level information about the OpenGitOps project763
-
Automated management of large-scale applications on Kubernetes (project under CNCF)4.19K
-
Ortelius is a microservice catalog that centralizes supply chain and DevOps Intelligence into one location. Use Ortelius to expose microservice version drift across clusters, aggregate SBOMs to 'logical' applications and track microservice usage across teams and environments. CDF incubating project.305
-
Development teams can now automate Kubernetes application delivery end-to-end.
-
The One CD for All {applications, platforms, operations}879
-
Overview and docs419
-
An open source build platform designed for continuous delivery.994
-
Hosted continuous integration and deployment service
-
Spacelift is a flexible management platform for Infrastructure as Code. It helps customize your workflows, automate manual tasks, reduce number of errors, improve security and auditability of your infrastructure.
-
Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence.9.07K
-
Powerful Continuous Integration out of the box
-
A cloud-native Pipeline resource.8.11K
-
Testkube provides a Kubernetes-native framework for test definition, execution and results. It decouples test artifacts and execution from CI/CD tooling and makes testing part of your cluster's state. Testkube is built and maintained by Kubeshop.1.02K
-
The Ember web client for Travis CI608
-
Weave GitOps enables the management of clusters and applications on scale with GitOps.
-
werf is a solution for implementing efficient and consistent software delivery to Kubernetes. It covers the entire CI/CD lifecycle and all related artifacts, glues commonly used tools (Git, Docker/Buildah, Helm, K8s) and facilitates best practices.3.82K
-
Woodpecker is a community fork of the Drone CI system.3.23K
-
Digital.ai helps enterprises achieve digital transformation by unifying, securing, and generating insights across the software lifecycle.
-
Baserow is an open source no-code database tool and Airtable alternative. This is a mirrored repository, the official one is hosted on https://gitlab.com/bramw/baserow.1.82K
-
CKAN is an open-source DMS (data management system) for powering data hubs and data portals. CKAN makes it easy to publish, share and use data. It powers catalog.data.gov, open.canada.ca/data, data.humdata.org among many other sites.4.11K
-
draw.io is a JavaScript, client-side editor for general diagramming and whiteboarding36.9K
-
A crazy fast analytical database, built on bitmaps. Perfect for ML applications. Learn more at: http://docs.featurebase.com/. Start a Docker instance: https://hub.docker.com/r/featurebasedb/featurebase2.51K
-
A lightweight client for managing MariaDB, MySQL, SQL Server, PostgreSQL, SQLite, Interbase and Firebird, written in Delphi4.19K
-
Easy to use open source fast database for search | Good alternative to Elasticsearch now | Drop-in replacement for E in the ELK soon6.85K
-
Open-source graph database, built for real-time streaming data, compatible with Neo4j.1.88K
-
Manage your photos with Piwigo, a full featured open source photo gallery application for the web. Star us on Github! More than 200 plugins and themes available. Join us and contribute!2.85K
-
Mirror of the official PostgreSQL GIT repository. Note that this is just a *mirror* - we don't work with pull requests on github. To contribute, please see https://wiki.postgresql.org/wiki/Submitting_a_Patch13.7K
-
An open source time-series database for fast ingest and SQL queries13.1K
-
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.24.2K
-
Rowy is an open-source low-code platform. Airtable-like UI for managing your database with cloud functions workflows in JS/TS, all in your browser.5.35K
-
Sandstorm is a self-hostable web productivity suite. It's implemented as a security-hardened web app package manager.6.56K
-
https://gitlab.com/samba-team/samba is the Official GitLab mirror of https://git.samba.org/samba.git -- Merge requests should be made on GitLab (not on GitHub)816
-
Apache Superset is a Data Visualization and Data Exploration Platform55.5K
-
TerminusDB is a distributed database with a collaboration model2.52K
-
An open-source time-series SQL database optimized for fast ingest and complex queries. Packaged as a PostgreSQL extension.15.9K
-
Build Mobile, Desktop and WebAssembly apps with C# and XAML. Today. Open source and professionally supported.8.11K












































































































































































{kind=link}
Subscribe to Open Source Businees Newsletter
Twice a month we will interview people behind open source businesses. We will talk about how they are building a business on top of open source projects.
We'll never share your email with anyone else.